Existing tools to search academic databases and online sources for relevant information are inefficient. I experienced this firsthand when doing research at GLAS Education, and its a sentiment even some UChicago professors that I worked with agreed upon.
Inspired by vector embeddings, which I read about while studying RAG, I wanted to transform the research process by creating a search engine that didn’t just find keywords, but actually understood what similar meaning looks like in context.
Features
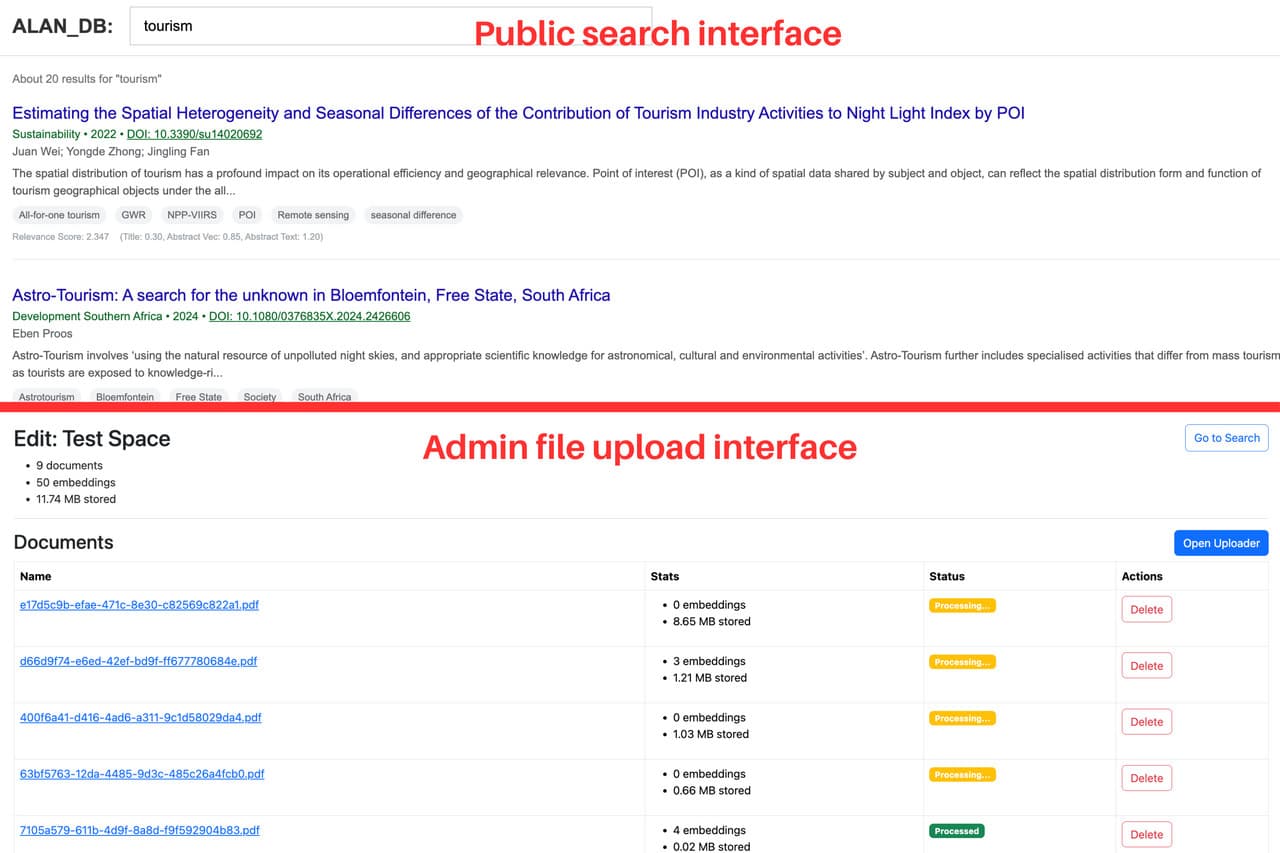
With CMSearch, you can describe a source or idea in your own words, even informally, and it will find the documents most relevant to the meaning of your query. This is especially helpful if you're unsure what exact keywords to search for or even the exact document you're looking for in the first place. It's a lot like using Google, but for your own documents and databases.
-
Spaces store collections of documents uploaded manually or imported from a source by any registered user
-
Embeddings are automatically generated for every paragraph and sentence, which get parsed from PDFs and text files
-
Search pages are created for every space, so you or anyone you invite can use it as much as you want
Simple? Yes, but it feels like magic to experience the underlying search algorithm in action; at times, it feels like it's genuinely reading your mind, exhibiting librarian-like intelligence rather than algorithmic rigidity.
Engineering
This site is fully server-rendered, built with FastAPI and Jinja2 in Python. The database is PostgreSQL with the pgvector extension. The two most interesting engineering challenges were generating embeddings and then searching them; the rest was a standard web app.
To generate embeddings, I used the OpenAI API with the text-embedding-3-large model. Before CMSearch gets to that point though, it has to parse documents into paragraphs or sentences. To do this even if PDFs didn't have native text content, I used a combination of pdf2image and Pytesseract to run them through OCR. To handle text that continues across multiple pages, I check for terminal punctuation and hyphenation to determine if the last line of one page should be merged with the first of the next. Sometimes, this logic errors, leading to weirdly merged or broken paragraphs; other times, it works, but includes writing that isn't actually related to the substance of the document (e.g. page numbers, footers, headers). To fix this, I used simple regex rules and OpenAI's GPT-4 to determine if a paragraph/sentence should be eliminated or kept.
To search embeddings, I embed the query with the same model as before and calculate the distance between that new vector with each in the database using the PostgreSQL/pgvector Euclidian (L2) distance operator. The user is shown the 10 closest documents, with pagination to request some th page. To make this operation as fast as possible on larger datasets, I created a Hierarchical Navigable Small World Graph (HNSW) index on the embedding column. This brings the algorithm down from to by building a multi-layer graph connecting similar vectors. At query time, it navigates this graph from coarse to fine layers, finding near-optimal matches while only examining a fraction of the original database.
Reflection
Anecdotally, I love using CMSearch for my own research efforts and the people I've shared it with have reported feeling the same way. Large language models feel somewhat magical when you really think about how far they've come, but they also feel like a black box. With vector embeddings, that black-box feeling is still there. It's clear how they emerge as a product of contextual similarity rather than opaque reasoning, but the fact that they capture meaning in context so well with this simplicity feels magical.
I've open sourced the project on GitHub so anyone can self-host it if they wish!
Screenshots